USP for FSWire Ltd ?
Clive Shirley
The Problem
Personal and business interactions and have now moved to the Internet leading to an explosion data that can be mined to generate operation insight for SMB and Enterprises alike. A 2013 IDC report, estimated that the world generates 1 quintillion bytes of data per day, yet we are only able to analysis less than 1% of this information regardless of vertical.
To utilise even a fraction of this data, businesses must go through a series of steps with identify and sanitise the information they are interested in.
This requires the following expertise:
- Domain, for the vertical(s) the business operates within, allowing said businesses to build rules that identify pertinent data.
- Data, to define patterns and models that can be used to match/find/process future pertinent data, as well as models that exclude irrelevant data.
- Engineering, to implement the necessary machine logic and processes to collect, sanitise and categorise content so that it can be used by the organisation to drive business decisions
- Business, to create the business intelligence that will utilise said data and drive business decisions
With this in place the storage and compute power required to process such vast amounts of data in real time is significant. Furthermore the aforementioned steps/tasks that an organisation must go through/implement are not static in nature, content structure changes daily, thus continued data analysis to determine optimal strategies and their implementation adds too the running costs of any solution.
At FSWIRE we solve this for pain points I through III, for every area in financial services
How FSWIRE solves this problem for customers
(The Twitter Example)
450M tweets per day (310K tweets/minute or 5.1K tweets/second - average) are pushed through the twitter Eco-system composed of any type of message content. Each tweet consists of unstructured text of 140 characters in size which may include embedded links to other information sources including web-pages and media. This equates to around 1 TB of message data, yet each message is augmented with a slew of additional content such as information about the author, location, tags etc. increasing data size to around 2 TB per day (2.1-2.3 MB/Sec) delivered as a stream of JSON structured data.
To process this one needs an effective/efficient mechanism for filtering the useful content (generally using text processing methodologies which are compute intensive). Subsequently content needs to be structured into a taxonomy fit for its business purpose.
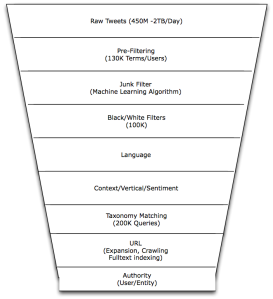 Funnel Filter
Funnel Filter
At FSWIRE we do this by implementing a specialised multi-stage funnel filter allowing the removal of noise at various stages resulting in a highly pertinent stream of data structure around a multi dimensional taxonomy (see figure: funnel filter).
To provide some clarity on processing requirements, one should understand that some tweets are discarded at most stages with the pre-filtering stage reducing content from around 450 to 50 million messages per day.
- Pre-filtering is an efficient phase but still requires each tweet to be processed/matched against each of our 130K pre-filtering rules, which equates to around 59 Trillion rule applications per day.
- Junk Filtering follows, which uses a Bayesian based machine learning model applied to each of the 50M resulting tweets.
- The Black/White list filters are compiled of around 100K rules that are also applied to each of the resulting 50M tweets (around 5 trillion rule matches).
- Our language analysis includes the use of bloom filters which allows us to identify and discard non-supported languages.
- Context and sentiment analysis utilize a cross-reference machine learning solution consisting of SVM (support vector machines) and Naive Bayesian models
- The taxonomy engine currently applies each of the 200K rule matches/queries to each tweet identifying which asset/market segment/jurisdiction a tweet belongs too (10 trillion query matches a day). This is a process intensive task as the taxonomy rules range from simple string matches through too multiple boolean like queries.
- The final stages identify the authority of a tweet based on its author and URL domain as well as analysing any linked web-page for context/sentiment and further entity information.
As we have outlined each stage is CPU intensive, particularly the stages that require extensive text processing. To achieve this, FSWIRE operates a cloud scalable solution currently employing 300 processing nodes solely for the implementation of the aforementioned stages (excluding any data storage infrastructure) which spread the processing of:
64 Trillion rule matches/day + 10 Trillion data queries/day
Unique Selling Point
Flexible: Whether you want to enable your users to be able to follow people, tickers, commodities, currency pairs, key words… the FSWIRE platform delivers relevant content in real-time via our streaming API. We can customise our platform so that your users are able to decide “how much filtering” they want (i.e. removal of noise, irrelevant tweets or tweeters)
Speed to Market: The FSWIRE platform has been under development for 2 years. Our platform has been designed from the bottom-up specifically for financial professionals. Via a streaming API customers are able to access this platform quickly and efficiently.
Cost Savings: FSWIRE is built on a fully-resilient and highly-scalable platform that is capable of analysing huge quantities of real-time data. We have invested heavily in the development of proprietary machine learning algorithm(s) for processing unstructured data, with the view that as the quantity and velocity of daily information increases so does their ability to influence the financial markets, the importance of having a solution that can extract the relevant information from “noise” is paramount.
Domain Knowledge: FSWIRE has been built by financial markets experts for financial markets professionals. We have used our domain knowledge to help us identify the pertinent information from the irrelevant information.
Compliant: Whether a bank, fund or general investment broker our solution is compliant with all financial regulations across all business boarders.
We do this so you do not have to !