FSWire Architecture
Clive Shirley
A number of our customers and readers have expressed an interest in understanding our technical stack and how they can leverage our API and raw data for business/financial decisions.
We have a classical web architecture with a number of autonomous services and delivery mechanisms allowing us to scale horizontally when load dictates while plugging in new features without impacting performance or the stability of the overall system. Utopia - well not quite in practice but it sounds good.
We use Ruby on Rails hosted on a Heroku stack for front end delivery of our social dashboard solution to both Mobile and classic desktop platforms. This enables us to dynamically scale based on load using some nifty in-house gems we have developed that leverage the Heroku API. As these are generally commodity components this is a no-brain er as we get a predictable scale-out cost proportional to load - web apps 101.
The more interesting stuff is what we do within our analytics backed and how we are able to consume the huge amount of social data that we do. Our backed stack is classic Ubuntu, Postgres, RabbitMQ, Redis, Mongodb and MapReduce mixing it up with custom daemons for our data consumption and processing pipelines. We server our back-end API through Rails leveraging this within our processing pipelines.
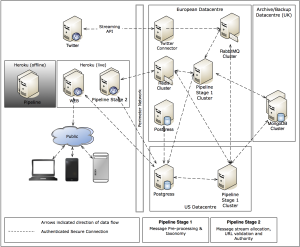
Communication and transitive state is handled via RabbitMQ and Redis. This split is generally historical and will be ratified in a future iteration of our infrastructure. These queuing technologies allow us to take data off the wire in real-time and push it into our staged processing pipeline.
Postgres is used for our high-level analytics and a huge Mongo cluster implements the aggregation and archiving of all social data collected for us to perform analysis on. MapReduce is our saviour for selecting and manipulating this huge volume of data into our numerous analytics and prediction pipelines.
Redis provides a natural cache solution for recent social data for application display/rendering purpose reducing the number of times we have to hit the twitter API.
All this allows us to scale out and process limitless (in theory) amounts of data. Current consumption of twitter accounts for around 1 TB of data per day, which we decorate with sentiment, links, user weighting, sector and a host of other features which results in the processing of somewhere around 2 TB per day using billions of data processing operations. Obviously we are only storing the useful data, but we must analyse everything to enable identification of trends and breaking events which are currently not explicitly tracked and would otherwise be missed.